In this post I’ll demonstrate how to load the Heterogeneity Activity Recognition CSV data set into a SQL database.
The dataset consists of a set of CSV files that are similar — but not identical — in structure, and if you want to make use of a dataset like this, putting it in a SQL database makes the data more accessible to explore.
From the abstract:
The Heterogeneity Human Activity Recognition (HHAR) dataset from Smartphones and Smartwatches is a dataset devised to benchmark human activity recognition algorithms …
The data set contains gyroscope and accelerometer data recorded from phones and wearable devices, both at rest, and during scripted activity like climbing stairs, riding a bike, and the like.
The data set contains two distinct portions:
- a still dataset, with sensor readings when the device is at rest in various positions
- an activity dataset, with sensor readings when carried by people performing certain activities
In this post, I’ll focus on importing the still data available as Still exp.zip from the download section into a Postgres 11 database.
Get Tweakstreet and solution files
You can download preview builds of Tweakstreet. Tweakstreet will always remain free for personal and evaluation use.
The solution files contain the completed import solution for both, still data and activity data.
Follow along screencast
I’ve uploaded a full-length screencast of the development process, if you wish to follow the construction process of the import solution more closely:
File system layout
The files in the zip file are laid out according to device orientation and model. Each model in turn can hold more than one device variant. Most of the devices are watches, mobile phones or tablets, with one interesting outlier being the x-sense device. The file for the x-sense device does not have a separate folder. This is what the unzipped file structure looks like:
So the data for the LG-Nexus4 in rest on its back is available in Phoneonback/nexus_4_2/LG-Nexus4.csv for example.
It is interesting to note that not all devices are present in each orientation. The iPhone 6 data is only available in the Phoneonback category for example.
Data Structure
The data structure of the CSV’s is documented as follows:
Each CSV file consists of 6 columns creation time, sensor time, arrival time, x, y, z. The six axes from the accelerometer is the x, y, z columns.
This seems like an easy import. But alas it is — like most data documentation — not quite right. Sampling through the different files, it turns out that sometimes the column layout varies a bit. Let’s snoop around:
The file Phoneonback/3Renault-AH/Samsung-Galaxy-S3 Mini.csv
We have columns: Creation_Time, Sensor_Time, Arrival_Time, x, y, z just as documented. The timestamps are integers, and the accelerometer data are decimal numbers. No surprises here.
The file Phoneonback/nexus4_2/LG-Nexus4.csv
We have columns: Arrival_Time, Creation_Time, x,y,z. Note that the sensor time column is missing and the arrival time and creation time columns have switched order. We’ll deal with it.
The file Phoneonback/x-sense.csv
The iPhone files contain the following columns Index , Arrival_Time, Creation Time, x, y, z
Here too we have an Index column holding integers. It’s also worth noting that the creation time is a decimal number with seven decimal digits. This stands out as the other devices produce integer timestamps. This fact will inform the choice of data type for timestamps when we load them into the SQL table.
The actual data structure
It seems like we have an understanding of the data structure in each file now:
- the full set of possible columns is:
Index,Creation_Time,Sensor_Time,Arrival_Time,x,y,z - the columns are named consistently across all files
- each file contains a subset of all possible columns in an unspecified order
Approach
I’ll be using Tweakstreet preview build 29 for the loading process. It’s free to grab in the download section of our website. I’m going load the data into a local instance of Postgres 11, but aside from the create table statement the same data flow works for Sql Server, MySQL, Oracle, DB2 or any other database with reasonable JDBC driver support.
Strategy
For loading this data set, I’d like to divide the problem into two smaller problems and solve each independently:
- find all files to load, and establish the metadata — orientation, model, device name — from the file path
- load an individual file into the database
I’d like to go bottom-up on this, and start with loading a single file into the database.
Loading a single CSV file
Parameters
The file loading data flow is a building block we want to invoke for each file that needs to be loaded. As such, it needs parameters that tell the flow which file to load. Additionally, the orientation, model, and device name are not part of the CSV file content, and I’d like the logic in the flow to just focus on the file contents. So orientation, model, and device name are also going to be parameters. We can supply default values to parameters, such that we don’t need to enter any data each time we run the flow when developing it:

Reading the CSV
We know that the columns in this data set are consistently named. So the natural approach is to configure the CSV Input step to read all possible column values by name, as opposed to column index, which we know varies across files.

If a column of the given name is present, it gives us the value, if it is not, it will give us a nil value, which sill become a NULL value in the database.
For example: reading the file Phoneonback/nexus4_2/LG-Nexus4.csv will give is nil values for the Index and Sensor_Time columns, because those are missing from the file, but the name-based mapping will return all other columns correctly:

The database table
The database table should hold all fields from the CSV file, with the addition of orientation, model, and device name.
This table structure seems adequate for a start:
I’ve renamed the Index column to sample_index to avoid issues using the reserved SQL word index as a field name.
I’ve made the timestamp columns fractional – since at least the iPhone data requires fractions – giving them a 32 total digits, with 12 digits after the decimal point.
The accelerometer values get 32 total digits with up to 20 decimal digits. These are somewhat arbitrary picks based on manual viewing of the data and the assumption that accelerometer data are internally doubles which means they have a maximum precision of ca. 18 digits, so 20 should be enough to not lose any precision.
Loading the records
The SQL Insert step takes incoming rows and loads them into the database table.

After loading a single file, the data looks as expected:
Loading all CSV files
Now that we have a flow that reads a CSV file when invoked, we need to find all files we want to read, and invoke that flow for each one. In addition to finding the file, we need to extract which orientation, model, and device name to use based on the loaded file’s path. A new data flow can take care of that.
Finding the files
I’ll use the Get Files step to find all *.csv files in our still data folder, and put the full path of each found file into the row stream.

Running the flow and previewing the data confirms that the correct files are found:

The next step is to extract the orientation, model, and device name from the path. This information is contained in the last three sections of the path. The file name — excluding the .csv extension – is the device name, the folder name is the model, and the parent folder of that is the orientation.
I’d like to drop the Phone prefix on the orientation so Phoneonbottom becomes onbottom etc.
We also have the complication that the x-sense.csv files don’t have a model folder. So instead of being located at Phoneonback/x-sense/x-sense.csv, to conform with the rest of the files, they exist directly in the orientation folder like so: Phoneonback/x-sense.csv
I’d like to call CSV files that exist directly under the orientation folder “orphans”, since they lack a proper parent folder. For orphan files, we’ll just reuse the device name as the model name. So for the x-sense.csv data both the model and device name will be x-sense.
To do the data extraction, I’ll use the calculator step, and use some standard library functions to extract the data.

This section in the screencast explains how the calculations were constructed:
The step splits the path into a list of parts based on either the / or character – which makes this data flow windows-compatible – and reverses them, so the file name comes first, its folder is second, its parent folder is next, and so on, making the root directory the last entry in the list.
The name of the device is extracted from the file name by replacing the .csv file ending with an empty string. We detect whether we are looking at an orphan file by checking two folders up. For a normal file this will be an oriantation folder like Phoneontop etc. For an orphan file this is will be our still data root: Still exp.
The model is usually the folder the csv file is in, but in case of an orhpan, we’re just reusing the device name. Similarly, the orientation folder name named orientation_raw above is either one folder up for orphans, or two folders up for regular files.
Finally the orientation name is the result of removing the Phone prefix from the orientation folder name.
The three results we want in the row stream are orientation, model, and device. These will be used as parameters when we execute our CSV loading flow.
Running the sub-flow
We are now ready to call the sub flow that loads a single CSV file. We have the file path of the file to load, the orientation, model, and device name. The Run flow step is executed for every file, and the corresponding parameters are passed in:

All together now
As a final touch, I’d like to re-create the still data table on every invocation of the master flow, such that there is no data duplication. The SQL Script step can take care of that by issuing the following statements:
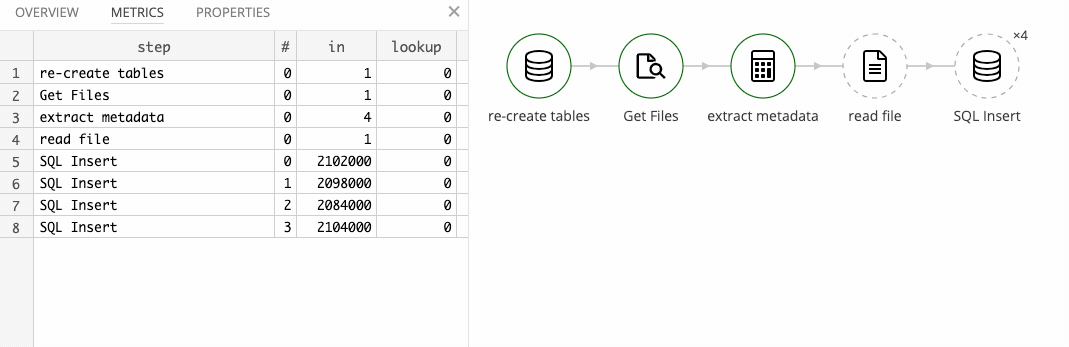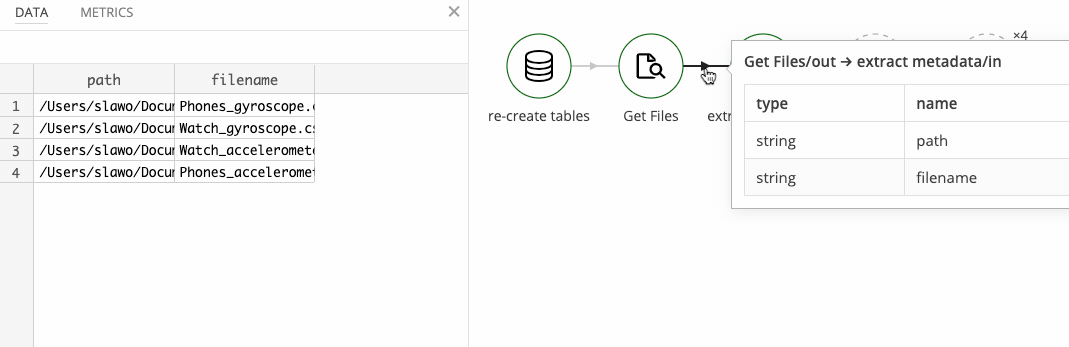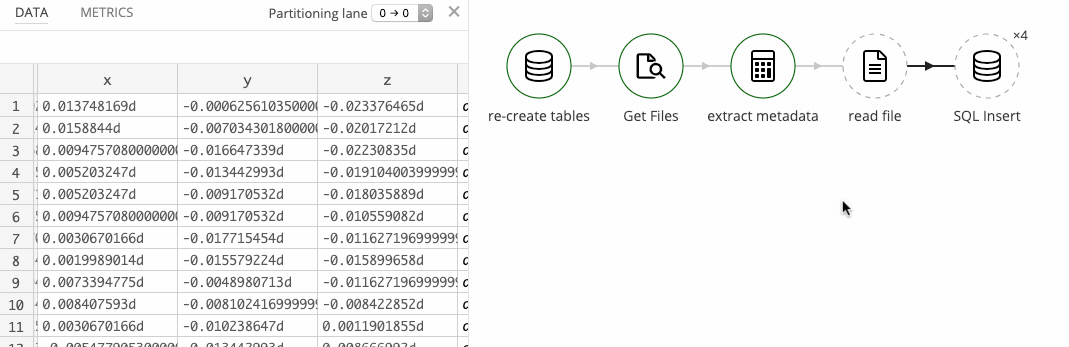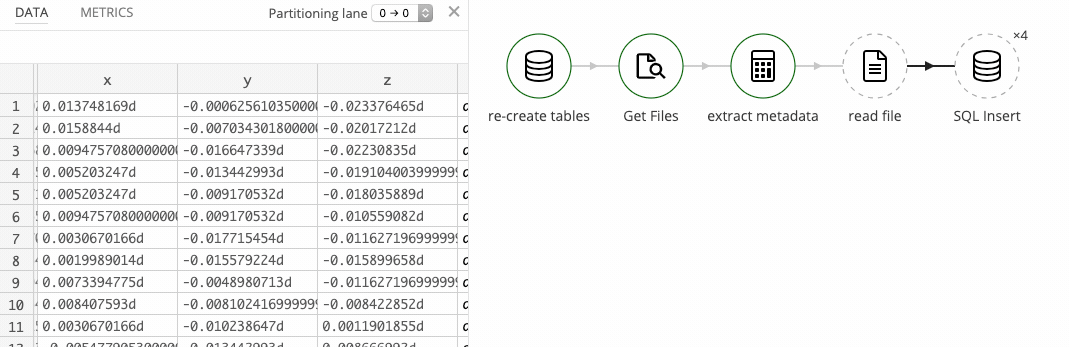
The completed master flow looks like this:

It completes in ~45 seconds on my laptop, and loads all 198 files into the database, amounting to 2,632,396 records.
A quick overview over all LG devices:
And a quick check of the average accelerator values of LG devices when laying on their back:
In the upcoming part 2, we’ll load the activity data. See you then!