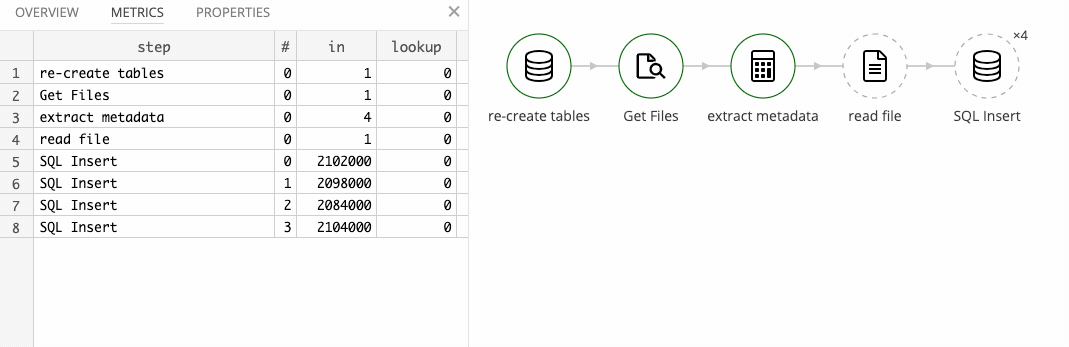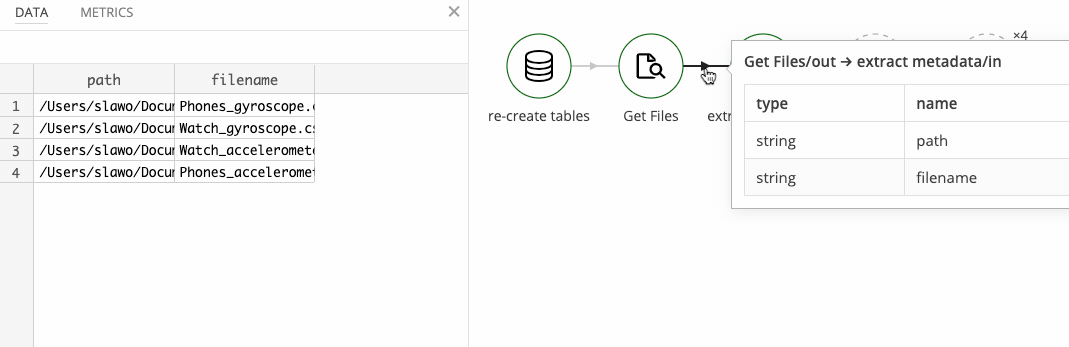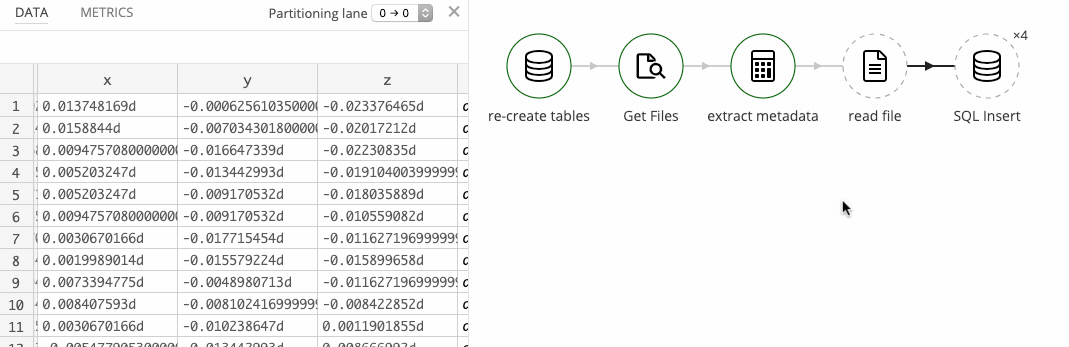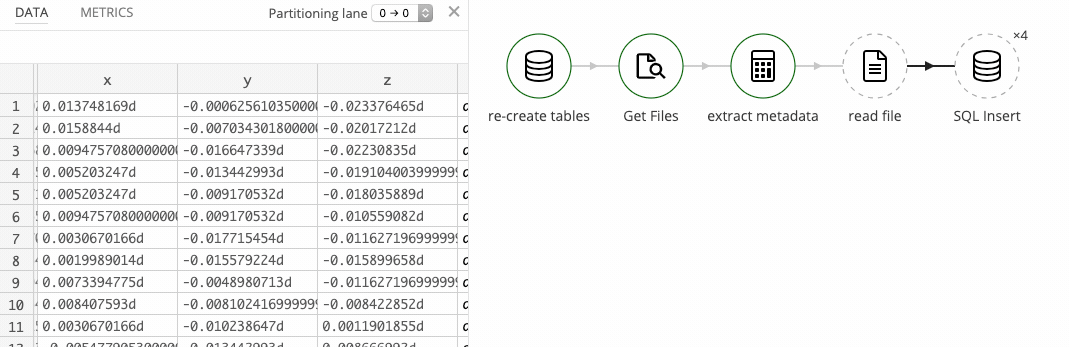
At Twineworks, we are devloping tweakstreet, a next-generation data processing tool.

Tweakstreet is similar to existing ETL and data integration tools, yet different in some key aspects. This post explains why we are making tweakstreet, how it is unique, and where you can get preview builds.
Data literacy vs. code literacy
I would like to address our rationale for creating a gui-driven tool to process data. In this argument I’d like to distinguish between data and code.
Data contains information
It consists of primitive types like numbers, dates or text, and it is usually structured as records or lists. When these records and lists are nested, they form data trees. Relationships between data entities are modeled using key fields. XML files, JSON data, tables in a database, spreadsheet tables, and any number of other data sources are all a concrete embodiment of just a few concepts.
The less formal overhead in the representation, the more self-evident the content of a piece of data: information is conveyed directly.
Data is semantically transparent
Code represents an algorithm or process
It consists of processing definitions or instructions. Depending on the programming language used, the concepts are vastly different. Imperative, object-oriented, functional, or hybrid languages offer a wide range of problem-solving methods. Software developers build entire careers based on understanding and mastering a subset of those approaches and related ecosystems.
A considerable amount of learning and practice is necessary in order to use any programming language idiomatically and efficiently. Something as simple as substring("hello", 1, 3) is highly ambiguous taken at face value:
- Is it a custom function, or a standard library function?
- Assuming the first argument is the start index: is it 0-based or 1-based?
- Is the second argument the length of the substring or the end index?
- If it is the end index, is it inclusive or exclusive?
- Is the end index 0-based or 1-based?
Note that the ambiguity does not originate from the parts "hello", 1, and 3, whose meaning it transparently clear. It’s the function call, the processing instruction, that requires detailed knowledge in order to understand correctly.
Code needs much context to understand
There are many more people who understand data, especially data from their business domain, compared to people who understand code. Data literacy is something that needs little training. It is not necessary to take JSON-certification courses, even though the format is capable of holding complex structures. Data is self-evident. Code literacy on the other hand requires a substantial investment. Entire careers are based on it.
We designed tweakstreet to let you work at the level of data
Viewing data is the primary feedback loop when working with tweakstreet. You see what data comes in, and see how data was transformed. You use predefined gui-elements to read, transform, and write data. You can use pieces of code to transform data manually if predefined gui-elements are not doing exactly what you need.

Using this approach, you focus on your data, with only sporadic moments when a custom piece of code is necessary, or just particularly convenient.
It is our belief that working with data should be open to people who do not wish to master a general-purpose programming language like python, nodejs, or java. Data people need not be coders in order to be effective.
Tweakstreet lets you do data engineering without requiring a computer science degree
Most data is not flat
A few decades ago the most common data structure has been the flat record. Relational databases were overwhelmingly the dominant way to store data, and flat records are a natural consequence of modeling data in fixed-structure tables. With the appearance of various NoSQL databases and coinciding developments in web technology, another data structure became very common: the data tree. Data sources today often provide composites of records, lists and primitive values, all of which potentially nest to form deeper structures.

Traditional data integration systems often still have a foundation of flat records as their primary unit of data, which makes it difficult to work with JSON-like data trees.
Tweakstreet supports data trees natively. You can work with arbitrarily nested lists, records, and functions operating on them out-of-the-box.
Composing flows
Data integration solutions are notorious for being difficult to compose from smaller pieces. Tweakstreet addresses the problem by treating all data flows like functions with side-effects: every flow has parameters and a return value.

For example, a flow that gets environment information like host name, or amount of CPUs, can accept a set of parameters specifying what information to get, and returns a structured value containing all acquired information. The caller flow receives the return value and processes it like any other piece of data.
This approach makes it possible to create self-contained, loosely coupled flows that are independently executable, making it easier to compose solutions from smaller pieces.
Isolating computation logic
Logic in data integration solutions is usually hard to extract and reuse. In a data integration tool, the tool itself provides a lot of processing logic in step configuration options. As a consequence, the logic performed through these steps is not testable unless you run the whole flow. The processing logic is encapsulated and locked within the step.
Tweakstreet adresses this problem by limiting functionality that is embedded in steps directly. In tweakstreet, most steps perform some sort of I/O like reading a file, or a side-effect like getting the current time. Steps avoid performing computations. Computations are handled by the formula language driving step execution: tweakflow

All step stettings and step results are tweakflow expressions that evaluate to values. Any non-trivial computation in a step can be extracted, and placed in an external library file. Once extracted it can be referenced from multiple flows, steps, etc.
Testing
Tweakflow comes with a test framework that allows you to write a test suite. Any logic in tweakflow libraries can be tested. At the same time, tweakflow libraries can be referenced from flows and steps, thus enabling high test granularity for logic used in data flows.
The test framework can also be used to execute flows. It is therefore possible to perform end-to-end tests of entire integration processes. The general pattern is as follows:
- reset any relevant external state, like database content
- run the flow under test, capture flow result value
- assert expectations in flow result value
- run a data collection flow, collecting and returning, but not verifying, any effects the tested flow performed, like changes in database tables
- assert expectations in collected data
Using this approach, the test suite can make a series of finely-grained assertions about expected vs. actual external state.

Flexibility
Tweakstreet is generally not opinionated on how to structure flows or process data. It does not limit your choices. There goal is to have sensible defaults, but data integration is a tricky business. There is no way for us to foresee how your data is structured, and how you might want to process it. We’ve seen some crazy raw data sources out there. We therefore believe that step configuration defaults should reflect the common case, while leaving you free to get creative, if you need to.
As a consequence of that philosophy, you can expect the ability to supply your own aggregator in the group by step. You can also supply your own sort comparator function in case you need a non-standard ordering of records. You can decide to read CSV lines a field at a time, or retrieve a list containing all fields per line, etc. The defaults are ui-driven and cover the most common use-cases, but if you need that extra level of control, tweakstreet will usually give it to you.

As a related idea most input steps allow you to read input data into a value as whole records, instead of spreading input fields to fields in the row stream. You can therefore create flows that are content-agnostic. You can extract data from database tables and files where you don’t care about the content as such, you just care about transporting the records to their place in data lake storage, for example.
Data driven flows
All settings on tweakstreet steps are tweakflow values. Flow parameters and records passing through a step are also values.

You can easily reference both flow parameters and data passing through a step to configure step using record values as they pass through.

For example, if you have a step that validates a field using a regular expression, that regular expression need not be hard-coded in the step configuration. It may very well come from a parameter, or even with the data, and be potentially different for different records in the dataset.
Similarly, if you have a flow that reads a CSV file, the exact delimiter and enclosing character can come from a data configuration source, and be different for each file.
This allows flows to be designed in a meta-data driven way. It enables you to build data integration solutions whose detailed configuration is governed externally. A typical meta-data driven solution looks up the set of rules it needs to apply in external storage, like a SQL database or web-service, before it proceeds with transforming the data. As a result, a single flow can potentially solve a whole class of data integration requirements if they are similar enough to be solved by variations in step configuration.
Instant feedback loop
When you’re working with tweakstreet, you can always follow the effect of your steps on data. You run your flow and view data as it passes between steps, giving you an idea of the work your steps do.

In case you’re prototyping a function, you can always call it and evaluate against test values to get instant feedback.

Pluggable
On a long enough timeline, every data project has to deal with data not supported by the data processing tool. Say a new data source is an obscure machine that speaks a proprietary TCP protocol.
Tweakstreet supports a Java SDK that allows you to create custom connectors and processing steps. You can always rely on custom steps as a fallback measure in case you need to connect to a data source using a non-standard interface.
A demo plugin implementing various steps is available on GitHub.

Preview builds
Preview builds of tweakstreet are available for download. New releases are published once a week. Releases are expected to be largely forward compatible.
Preview builds are free. The general availability version of tweakstreet will remain free for evaluation and personal use.