This is the second part of a two-part series about loading the HHAR CSV data set into a SQL database using Tweakstreet.
The first post goes into detail on how to load the still data part. The challenge there is that there are 198 files with similar, but not identical file structures.
This post deals with activity data. This data is set consists of over 33.7M records. But these records are split over only four files, and all four files share the same structure.
Get Tweakstreet and solution files
You can download preview builds of Tweakstreet. Tweakstreet will always remain free for personal and evaluation use.
The solution files contain the completed import solution for both, still data and activity data.
The input files
The activity data set consists of the following files:
The file structure is as follows:
The target table
I would like to extract the device type and the sensor type from the file name, and keep all fields from the files. The following table structure holds all that information:
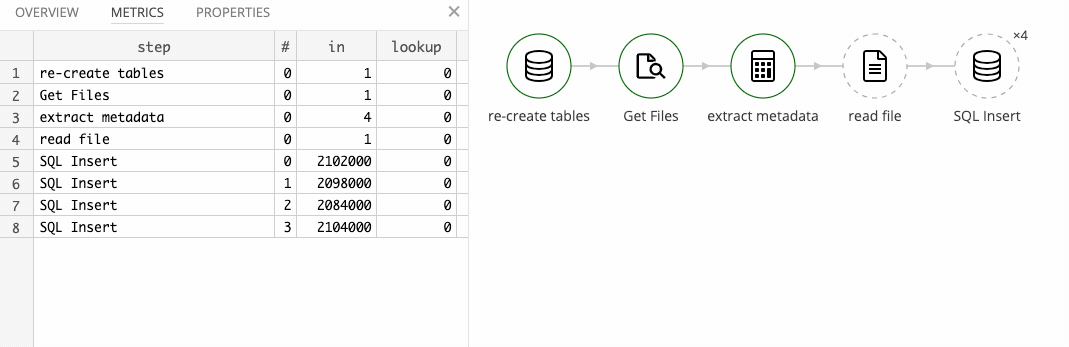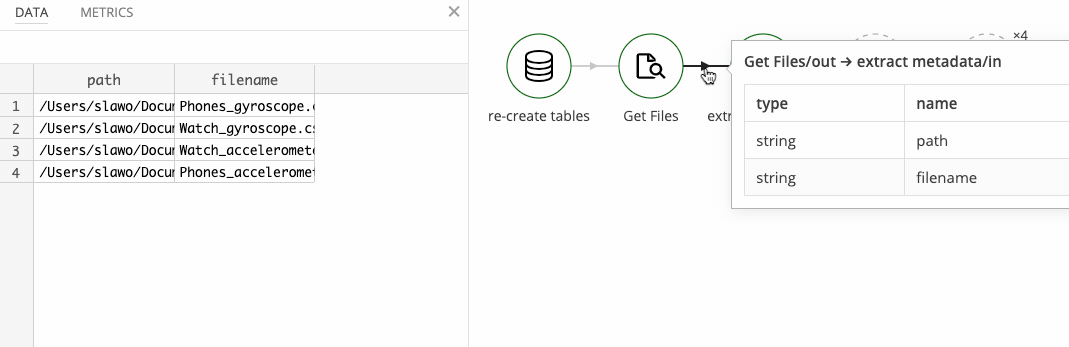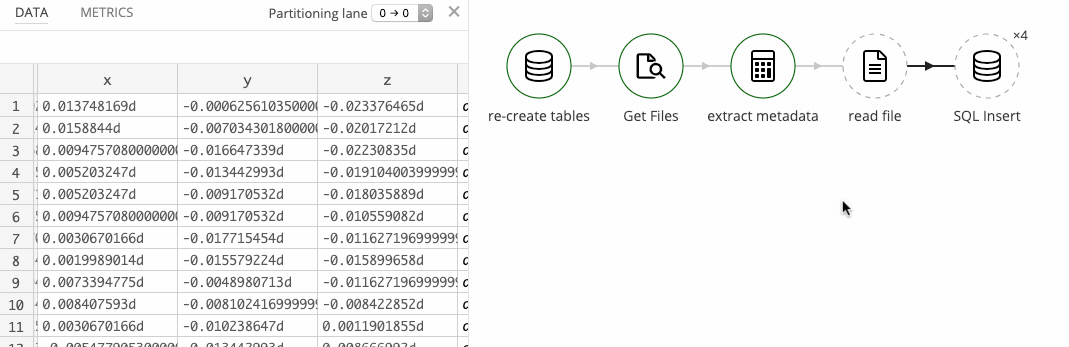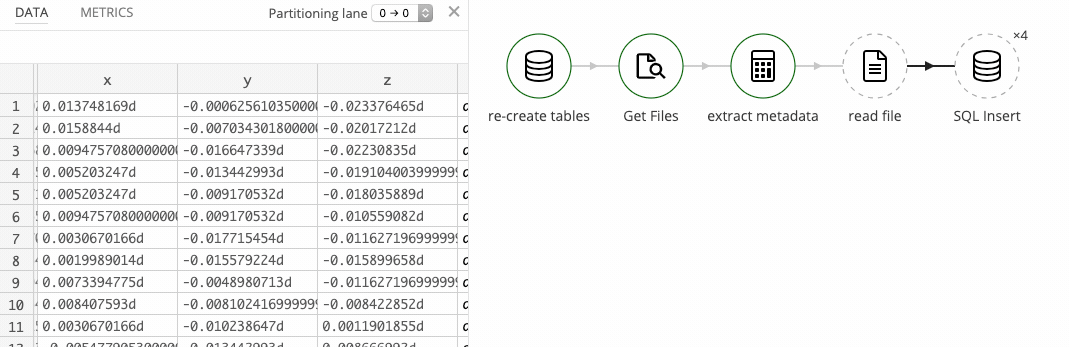
The data flow
The strategy for the flow is:
- re-create the activity table
- find all files the load
- extract device type and sensor type from file name
- read records from file
- insert records into database

Re-creating the table and getting all *.csv files works just as it did in part 1. Extracting the metadata is also similar to meta data extraction from part 1. We split the file name on _ and . characters and use the first and second part for the device type and sensor type.
A short mapping takes care of mapping Phones to phone and Watch to watch. Any unexpected values are left as they are, although at this point it might also make sense to throw an error if unexpected values are encountered.

Reading the records
Reading the actual records from the files is straightforward, with only one little snag: some of the values use scientific exponent notation.
We have a mixed set of formats for the x, y, and z columns, and we need to accommodate that. Examples of the formats to expect are:-0.7647095 and 4.5776367e-05
We have two choices here:
- Simply do not use any parser function, and cast the strings to decimals as they are. The number formats are common enough that the tweakflow language supports casting strings to decimals using both of these formats. A quick check in the tweakflow repl proves it:
- Use a specific formatter function that allows optional scientific notation.
The first option works fine, but has the downside of being slightly less efficient. A specialized formatter accepting a defined format is always faster than the cast which accepts a variety of valid formats. We’re importing ca. 33.7M records × 3 decimal values, so we’re at ca. 100M parsing operations. A specialized formatter function might be noticeably more efficient.
The format string allowing exponential notation is #,##0.#E0 and interestingly, the exponentiation prefix in the format is locale dependent. In the en-US locale it is the upper case E character. Lower case e is not accepted. To have our numbers parse successfully, we can either create our own parser that accepts a lower case e through the decimal symbols parameter, or we just upper case the whole string before parsing. I chose to be lazy and go for the upper case operation, yielding the following configuration for reading the CSV.

Inserting the records in parallel
We’re inserting 33.7 million records. I’m also talking to a database on the local network, so things should go faster if we ran multiple threads in parallel. While some of our threads are waiting for network I/O, other threads can work on separate network connections and push data out as fast as they can. My laptop has 4 CPU cores, and I am loading data into a database on a fast local network. My guesstimate is that around 4–8 parallel connections should be somewhere in the sweet spot for top performance. Right-clicking the step allows me to set the number of parallel instances I want to run:

Running the flow
All that remains is to run the flow, sit back, and watch the database table fill up.

A couple of minutes later all rows are loaded: