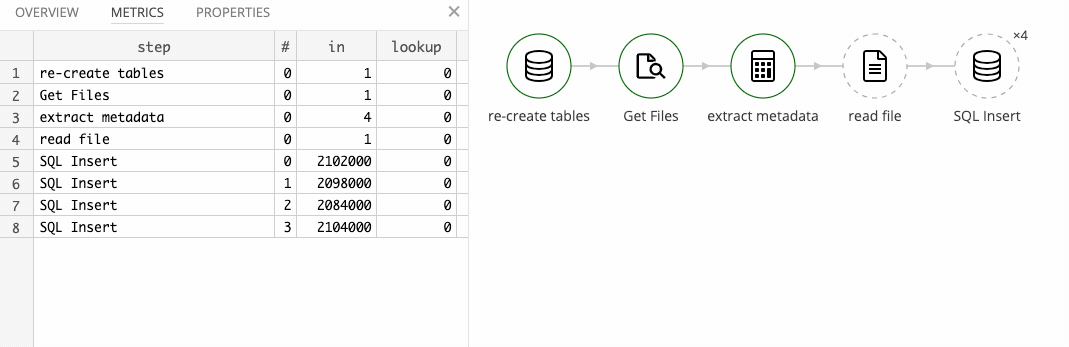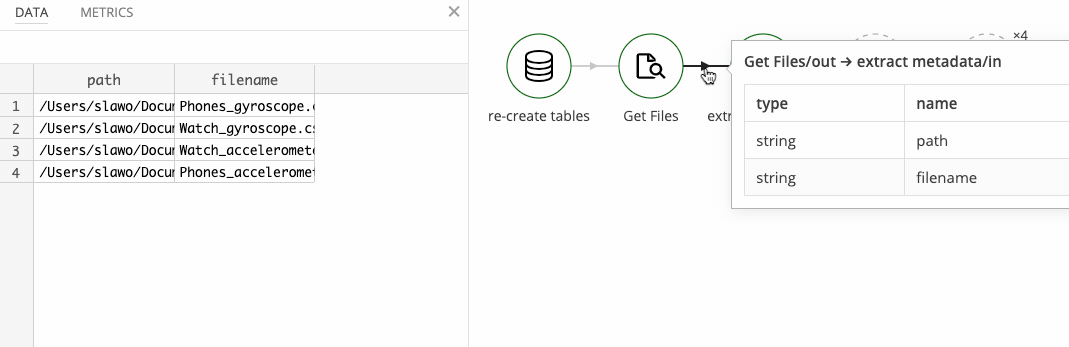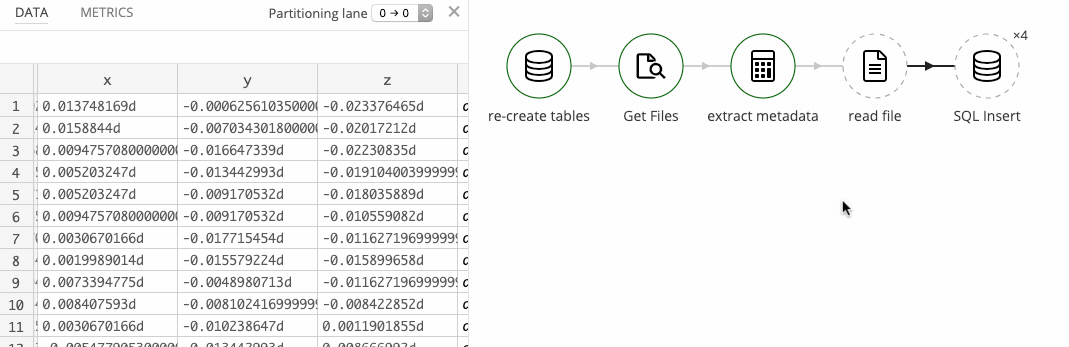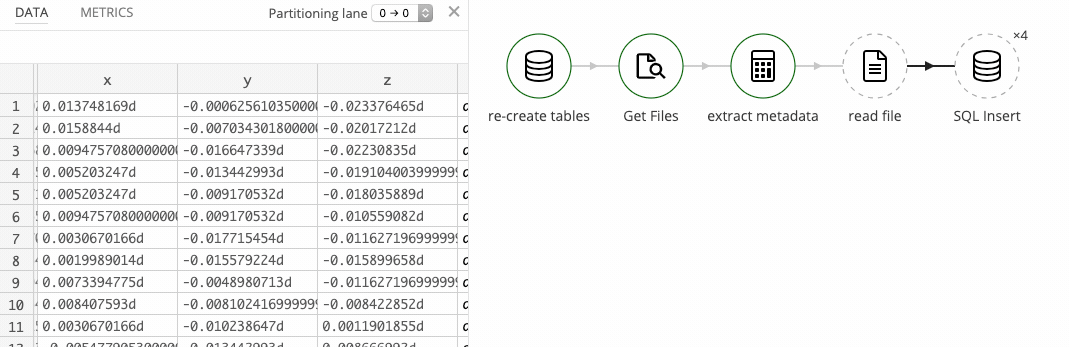
This article is about performance tuning data pipelines created with the Tweakstreet data automation tool.

Database steps in Tweakstreet often involve conditional lookups and writes: the Insert or Update step, the Junk Dimension step, and the Slowly Changing Dimension step are typical examples.
These steps need to look at the contents of a table, and conditionally decide whether to insert or update some records. Performance of such steps is almost entirely determined by the amount of round-trips to the database.
We want to minimize the queries issued to the database, and the cache and Bloom filter help with that.
Insert or Update
Let’s look at the the Insert or Update step. Given a set of key values it needs to determine whether to insert a new record, or update an existing one.
The simplest approach — when both cache and Bloom filter are off — is to:
- select the record with given keys from table
- if it exists, check if it needs updating, and perform update if necessary
- if it does not exist, perform an insert
This approach has the downside of issuing a lookup query per row. Even the database server is local to the running process, the overhead gets quickly out of hand.
We should be able to improve performance by using the cache and Bloom filter, but before start twiddling knobs let’s establish our test setup.
Test Setup
I have a MS SQL server on the local network — not the local machine — we want the I/O overhead to be felt keenly for this test.
I’m loading an empty table with 100,000 rows from a csv file. All records have distinct keys.

I’m loading another 100,000 rows from another csv on top of that, 80% of which are identical, 10% are updates, 10% are inserts.

This process simulates a typical scenario of maintaining a snapshot of last seen records. I’m using the Insert or Update step for both loads.
I’ll ignore the fact that instead of using Insert/Update, bulk loading the first csv file into the table is the rational thing to do. We’re interested in relative differences in performance using different caching settings, so we’ll play dumb for this test.
The test records have the following structure:
I’ve uploaded my test files, so you can play with the flows and data yourself.
Baseline: No Cache, No Bloom Filter
Initial Load: the step does 100,000 lookups — each returning an empty result — and follows up with 100,000 inserts.
Time: 03:27
Update load: the step does 100,000 lookups, and issues 10,000 updates and 10,000 inserts. The rest of the records are identical and after the lookup confirms they are identical, no further action is taken.
Time: 02:10

With this performance as a baseline, let’s see what we can do to improve it.
The Cache
The cache holds rows the step has retrieved from the database, indexing them by record keys.
When an incoming row is processed, the cache is checked for an entry with the corresponding key values. If there is such a row in cache, it is used instead of looking it up in the database. If there is no such row in cache, it is looked up and stored in cache for later.
Let’s turn on the cache.

Cache Enabled, No Bloom Filter
Just enabling the cache does not improve speed in our case. The cache is initially empty, it accumulates rows over time, and it starts paying off only if the same keys occur multiple times in the row stream. In our case that never happens.
Other cases — like filling a junk dimension — can benefit from a slowly building cache. But for our scenario we need to pre-fill the cache in order to benefit from it.
For us, performance does not change. We’ve just added some overhead for cache management.
Initial Load: 3:27, Update Load: 2:11

Perfect Cache, No Bloom Filter
We have the option to fill the cache with all table rows before row processing starts. If the table in question fits into memory, this results in very good speed improvements.
The step recognizes when we create an unlimited-sized cache and pre-fill it with all rows. It knows we’ve created a perfect copy of all table contents in cache. Now every row processed checks the cache. If a row is found, it is checked and updated if necessary. If it is not found in cache, the step knows the row is not present in the table either, can skip the lookup, and go straight for the insert.
Initial Load: 1:43, Update Load: 0:24

Limited Cache, No Bloom Filter
Pre-filling the cache with the entirety of a database table is a luxury we have for relatively small tables only. Say up to a couple million rows or so. Beyond that, the rows simply won’t fit into memory. To mitigate that fact we can limit the size of the cache, and the step will evict least-recently used rows on a best-effort basis.
However, we often have information about what is being loaded. Say we know we’re loading a customers snapshot and based on the data source, we know there’s only US customers in it. We can tailor the cache to pre-fill with US customers only. If we can manage to pre-fill the cache with the slice of table rows relevant to what we’re loading, database lookups will be much less frequent.
For our scenario, I’m fitting the first 50.000 records into cache by id. The lowest ids come first from file, so the initial batch will be satisfied by cache. The rest will have to hit the database.
Initial Load: 3:28, Update Load: 1:17

Limited Cache, With Bloom Filter
Another way to save unnecessary database lookups is to enable the Bloom filter. So. What does that do?
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970…
Nah, just kidding. Short version: a Bloom filter is a low-overhead way of checking whether a record is in the database table or not. Think of a Bloom filter as a leaky set of values. You can put a bunch of keys in. When asked whether a key is in the set, the Bloom filter responds with “maybe” or “nope”.
The bigger the size of the Bloom filter, the better it can distinguish between the two. The size of the filter should be close to the amount of distinct keys in our fully loaded table. The size is given in bits. A Bloom filter of size 10,000,000 occupies ca. 10,000,000/(8 * 1024 * 1024) MB ~ 1.2 MB plus some constant overhead in memory. Hence: space-efficient.

How does the Bloom filter work? In approximation: it remembers a condensed fingerprint of each item passed in. The fingerprint is generated by hash functions. There’s no hard guarantee that fingerprints are unique for each unique item passed in — there’s some partial overlap between them — so when you pass an item that matches fingerprints the filter has seen before, it says that it “maybe” knows about the item. If the fingerprint does not match anything seen before, the filter can confidently say: “nope”
When we enable the Bloom filter on the step, it initially fetches all distinct keys from the table and puts them in. When the step starts processing rows, it checks the Bloom filter for the current row’s key values.
If the Bloom filter gives us a “nope”, we know we can skip the lookup and do the insert. We put the keys into the Bloom filter, and move to the next row.
If the Bloom filter gives us a “maybe”, we have to ask the database for the record to be sure whether it exists or not.
The Bloom filter is most useful when it spares us the lookup trip to the database. We want to enable it when we’re expecting many inserts, and we can’t dedicate the memory required to keep a complete cache during the loading process. Insert heavy loads are much more practical with the Bloom filter enabled.
Let’s keep our limited cache on, and check how much the bloom filter can help.
Initial Load: 1:44, Update Load: 1:08

Partitioning the Load for Sequential Small Perfect Caches
Say we have space for 50.000 records in cache. We’ll optimize our loading scenario to be as efficient as possible.
For the initial load, we’ll just enable the bloom filter. No cache necessary. The bloom filter is going to guard against most lookups.
I’ll split the update load into three cache-efficient loads executed in order. We’ll partition the load on id mod 3 which puts every record into partition 0, 1 or 2. We’ll run three times, each time only loading records from the relevant partition. We pre-fill the cache with table records that fall into the same partition, and we should have pretty good overall performance.
This pattern can be further generalized such that the number of partitions we want becomes a parameter, and we iterate over the partitions we need to load.
Initial Load: 1:44, Update Load: 0:26

Conclusion
Let’s have a look at the performance results.

Enabling the Bloom filter definitely pays off for initial loads. In update loads, it depends on the amount of expected inserts. The more new keys, the more helpful the Bloom filter will be.
As for the cache, a perfect cache is optimal, but can be approximated by a sequential approach, where we load only part of the table at a time.
I expect that performance numbers scale almost linearly — OK n*log(n) — with the amount of records processed. So extrapolating from our test with 100,000 records to 1,000,000 records, we’d look at a load that takes almost an hour baseline vs. just fifteen minutes optimized.
A good look at the cache and Bloom filter config can make the difference between fitting inside a batch loading window or not.
Want to try it yourself?
Grab the latest Tweakstreet build from the download page, and the test files I’ve been working with. You’ll have to set up your own database connection to play with, but other than that everything should just work.